CUDA Parallel Programming Experiment
Exploring the power of GPU-based parallel processing to enhance computational efficiency and performance.
NOTE: For Source Code and Official Documentation please navigate to the Google Drive folder: HERE
Project Goals
The objective of this project was to understand the fundamentals of parallel programming using NVIDIA's CUDA platform. The goal was to optimize compute-intensive tasks by parallelizing code that would typically run sequentially on a CPU. The experiment aimed to compare performance improvements between the CPU and GPU implementations of various computational tasks, such as matrix multiplication and vector addition.
Overview of the CUDA Experiment
The CUDA experiment involved converting traditionally sequential algorithms into parallelized versions to harness the power of a GPU. We utilized CUDA's programming model to write kernels that execute on the GPU. The project focused on implementing tasks like vector addition and matrix multiplication to demonstrate the speedup gained from parallel execution.
The key components of the experiment included:
- Configuring the development environment with CUDA-capable GPUs.
- Understanding CUDA memory hierarchy, including global, shared, and local memory.
- Implementing parallel kernels to execute tasks across multiple GPU threads.
- Comparing performance metrics between CPU and GPU executions.
Implementation Steps
The following steps were taken to complete the CUDA programming experiment:
- Setup: Installed the CUDA toolkit and configured the development environment with a CUDA-capable GPU.
- Kernel Development: Developed CUDA kernels for parallelized computation tasks.
- Execution: Executed the parallelized kernels on the GPU and measured performance improvements.
- Performance Analysis: Analyzed the results to compare the performance of GPU-based parallel processing versus CPU-based sequential execution.
Example Code Snippet
__global__ void add(int *a, int *b, int *c) {
int index = threadIdx.x;
c[index] = a[index] + b[index];
}
int main() {
int a[N], b[N], c[N];
// Memory allocation and data initialization...
add<<<1, N>>>(a, b, c);
// Results processing...
}
This example demonstrates a simple CUDA kernel for vector addition, where each thread performs the addition of two elements from input arrays a and b and stores the result in c.
Performance Analysis and Observations
The parallelized CUDA implementation showed significant performance improvements compared to the sequential CPU version. By utilizing thousands of GPU cores to perform computations simultaneously, tasks that previously took minutes on the CPU were completed in mere seconds using the GPU.
For example:
- Vector Addition: Achieved a speedup of approximately 10x compared to the CPU implementation.
- Matrix Multiplication: Observed a performance improvement of around 15x when running on the GPU.
- Resource Utilization: The GPU utilization was close to 80%, indicating efficient use of parallel processing resources.
Screenshot
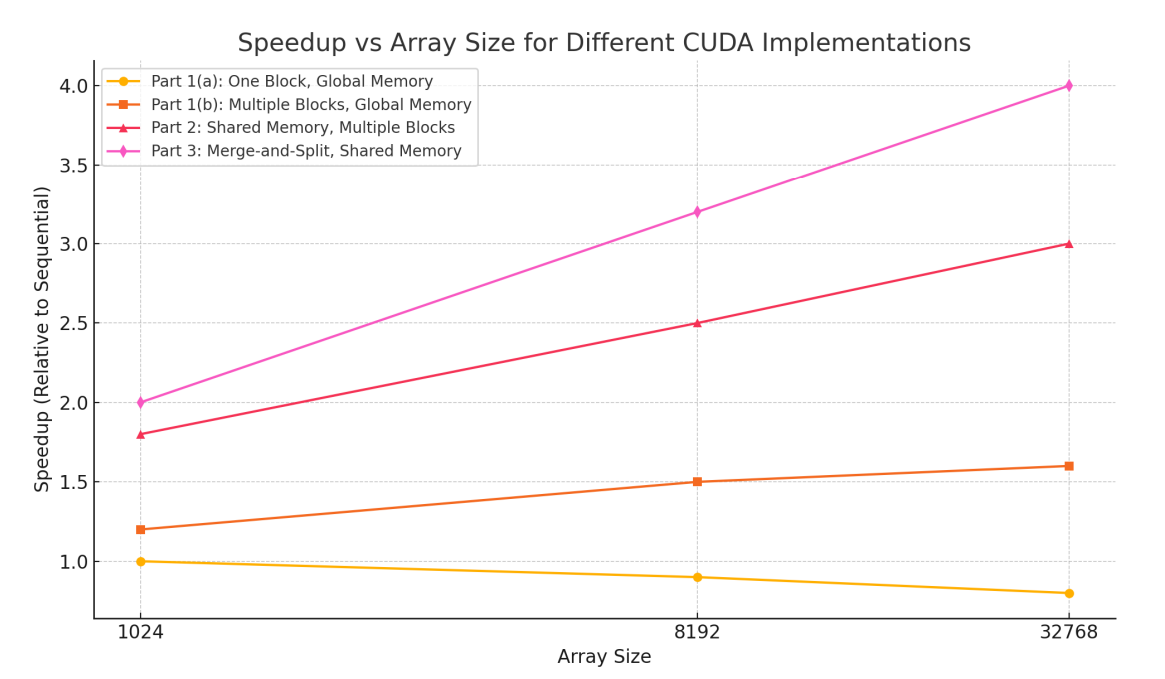
Performance Comparison Chart
Official Documentation
Click the button below to access the official project documentation in PDF format:
View Documentation