Setting Up a Hadoop Cluster on Chameleon Cloud
Overview
As a team of four, we successfully set up a Hadoop cluster on the Chameleon Cloud platform. This was done to process large datasets efficiently using Hadoop's MapReduce framework. Below are the key steps and configurations we implemented:
Key Steps
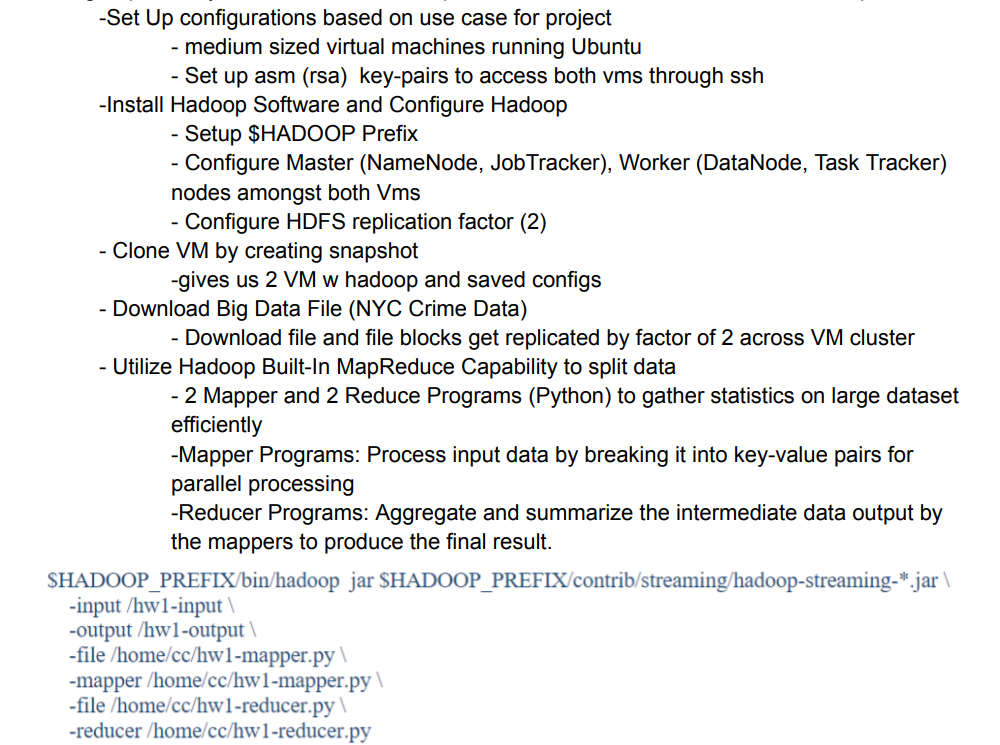
- Set up medium-sized virtual machines running Ubuntu, configured with RSA key pairs for secure SSH access.
- Installed and configured Hadoop software:
- Set up HDFS replication factor to ensure fault tolerance.
- Configured the Master node (NameNode, JobTracker) and Worker nodes (DataNode, TaskTracker).
- Created a VM snapshot to replicate configurations across the cluster.
- Downloaded and distributed NYC Crime Data files, replicating them across nodes.
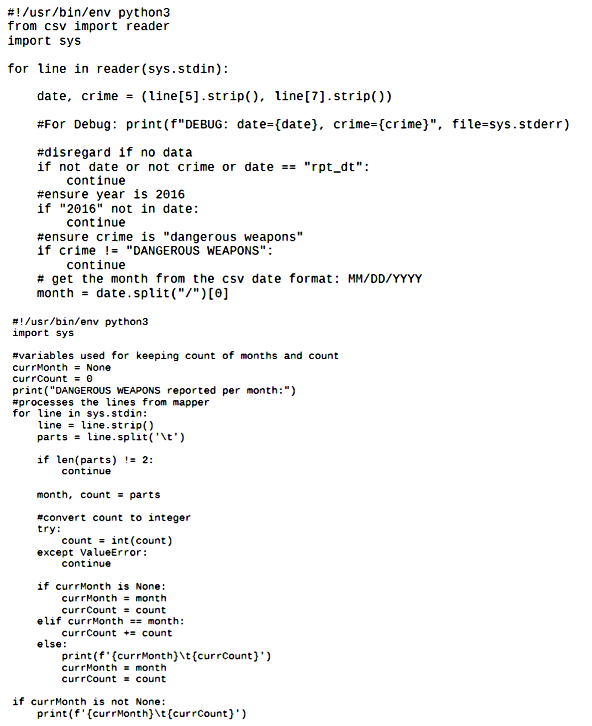
- Implemented MapReduce programs to process data:
- Mapper: Broke input data into key-value pairs for parallel processing.
- Reducer: Aggregated and summarized intermediate outputs.
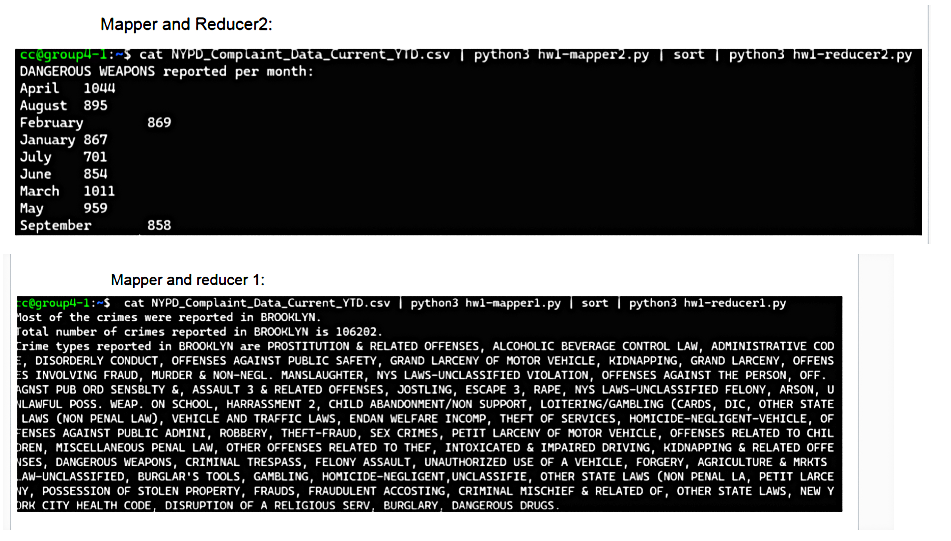
Screenshots
Below are screenshots demonstrating our setup and results:
Hadoop Configuration on Chameleon Cloud
Map-Reduce Python Code Snippet
Output